![[Database] 데이터 집계 - GROUP BY](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbc3Rak%2Fbtrtb16fr2E%2FgGSj1X118Px3vsrgJ2KJDk%2Fimg.png)
GROUP BY 절
GROUP BY절은 WHERE 절과 ORDER BY 절 사이에 위치해 집계할 대상 컬럼이나 표현식을 명시해주면 된다
SELECT station_name
FROM subway_statistics
WHERE gubun='승차'
GROUP BY station_name
ORDER BY station_name;해설) subway statistics이라는 테이블로 부터 gubun이라는 컬럼이 승차인 애들을 station_name이라는 컬럼을 기준으로 묶어서 집계해봐라. 그렇게 묶인 데이터를 station_name을 기준으로 오름차순 정렬해서 보여줘라

집계 함수
| 함수 | 의미 |
| COUNT(expr) | expr의 전체 개수를 반환한다. |
| MAX(expr) | expr의 최댓값을 반환한다. |
| MIN(expr) | expr의 최솟값을 반환한다. |
| SUM(expr) | expr의 합계를 반환한다. |
| AVG(expr) | expr의 평균값을 반환한다. |
| VARIANCE(expr) | expr의 분산을 반환한다. |
| STDDEV(expr) | expr의 표준편차를 반환한다. |
Group By 예시
Q) 지하철 승객 데이터의 갯수, 최소, 최대, 합계, 평균을 출력하라
SELECT COUNT(*) cnt
,MIN(passenger_number) min_value
,MAX(passenger_number) max_value
,SUM(passenger_number) sum_value
,AVG(passenger_number) avg_value
FROM subway_statistics;해설) subway statistics 테이블로 부터 데이터 갯수를 세서(COUNT(*)) cnt로 넣어주고 passenger_number 컬럼에 해당 집계함수를 적용해서 각 변수에 넣어준 걸 나한테 반환해줘라.
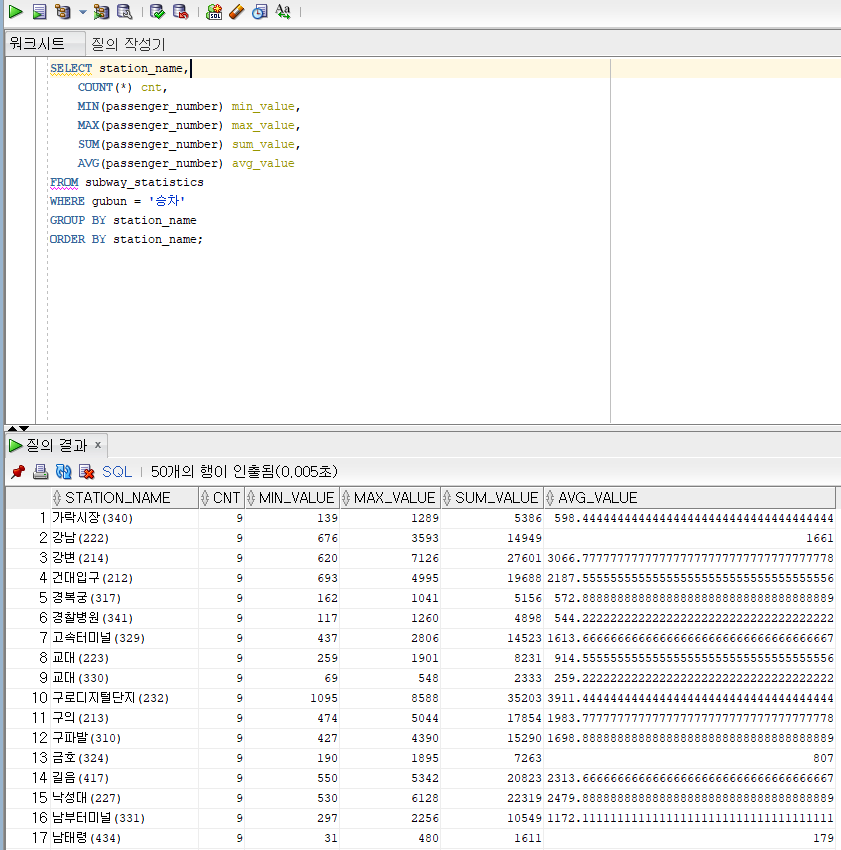
Q) 지하철 역별 승차인원 통계를 내라
SELECT station_name,
COUNT(*) cnt,
MIN(passenger_nubmer) min_value,
MAX(passenger_number) max_value,
SUM(passenger_number) sum_value,
AVG(passenger_number) avg_value,
FROM subway_statistics
WHERE gubun = '승차'
GROUP BY station_name
ORDER BY station_name해설) subway statistics이라는 테이블에서 station_name, 갯수, 최솟값, 최댓값, 합, 평균을 뽑아낼 건데 일단 gubun컬럼이 승차인 애들만 뽑을거다. 그리고 그렇게 뽑아낸 데이터 들을 station_name을 기준으로 집계를 하고 station_name의 오름차순으로 정렬해서 나한테 보여줘라.
Q) 구로 디지털 단지역 시간별 승하자 조회
My Solution
SELECT station_name,
boarding_time,
gubun,
COUNT(passenger_num) cnt,
MAX(passenger_number) max_value,
MIN(passenger_number) min_value,
SUM(passenger_number) sum_value
FROM subway_statistics
WHERE station_name like('구로디지털단지%')
GROUP BY station_name, boarding_time, gubun
ORDER BY station_name;Answer
SELECT station_name,
boarding_time,
gubun,
MAX(passenger_number) max_value,
MIN(passenger_number) min_value,
SUM(passenger_number) sum_value
FROM subway_statistics
WHERE station_name in ('구로디지털단지(232)')
GROUP BY station_name, boarding_time, gubun
ORDER BY station_name, boarding_time, gubun;차이점
- COUNT를 안 넣었다. COUNT는 원하는 목적에 필요하지 않은 정보이다. 물론 해당 값이 몇 일 동안 집계된 데이터 인지 파악하는데 필요하겠지만 이는 AVG로 대체 될 수 있다고 생각한다. 하지만 이는 쿼리 작성자에게 필요하지 않은 정보인거 같다.
- WHERE 조건이 다르다.
나는 구로디지털 단지라는 것만 알았기 때문에 저렇게 작성했기 했다.
속도 비교- WHERE like

- WHERE in

- WHERE like
확실히 in으로 찾는게 빠르다.
Q) 출근 시간에 가장 많이 하차하는 역은
My solution
SELECT station_name,
boarding_time,
gubun,
MAX(passenger_number) max_value,
MIN(passenger_number) min_value,
AVG(passenger_number) avg_value
FROM subway_statistics
WHERE boarding_time BETWEEN 6 AND 9
GROUP BY station_name, boarding_time, gubun
ORDER BY avg_value DESC;
Answer
SELECT station_name,
boarding_time,
gubun,
MAX(passenger_number) max_value,
MIN(passenger_number) min_value,
SUM(passenger_number) sum_value
FROM subway_statistics
GROUP BY station_name, boarding_time, gubun
ORDER BY 6 DESC;
차이점
- sum을 사용했다. 이건 사용자 의도에 따라 다른 거 같다.
- where절을 쓰지 않았다. 이는 데이터에 대한 나의 이해 부족인거 같다. boarding time은 전체 데이터에서 7 8, 9 중 하나로 정해져있다. 따라서 where절을 굳이 쓸 필요가 없었던 것이다.
- order_by를 숫자로 표현했다.
- 이는 취향 차이 인거 같다. 속도 차이가 없기 때문이다. 저자는 이렇게도 order by를 쓸 수 있다는 것을 표현하고 싶어서 쓴거 같다.
DISTINCT 사용
DISTINCT 컬럼명을 사용하면 해당 컬럼에 들어가 있는 값을 중복값을 제외한 유일한 값들만 조회되어 GROUP BY 절을 사용한 효과가 난다.
Q) 첫번째 코드를 DISTINCT를 사용해서 바꿔 본다면?
SELECT DISTINCT station_name
FROM subway_distinct
WHERE gubun='승차'
ORDER BY station_name;본 글은 '누구나 쉽게 SQL'이라는 책을 읽고 정리한 내용입니다.
http://www.yes24.com/Product/Goods/74311553
누구나 쉽게 SQL - YES24
설명은 쉽게 + 기본기는 튼실하게두 마리 토끼를 다 잡은 SQL 입문서!『누구나 쉽게 SQL』 은 데이터베이스의 기초부터 SQL 사용법과 동작 원리까지 반드시 알아야 하는 핵심만 담은 도서이다. 핵
www.yes24.com
더 많은 내용을 알고 싶은 분은 위의 책을 보시길 바랍니다.
긴 글 읽어주셔서 감사합니다.
틀린 부분이 있으면 댓글을 달아주시면 감사하겠습니다.
📧 : may3210@g.skku.edu
'개발 > Oracle' 카테고리의 다른 글
| [Database] 집합 쿼리 (0) | 2022.02.15 |
|---|---|
| [Database] 데이터 집계 - HAVING (0) | 2022.02.15 |
| [DataBase] SQL 연산자와 함수 (0) | 2022.02.15 |
| [Database] 데이터 조회, SELECT 문 (0) | 2022.02.14 |
| [Database] 데이터 입력과 삭제 (0) | 2022.02.14 |