
이번 스터디는 다음과 같은 순서로 이어졌습니다.
1. NLP 복습
2. Seq2Seq
3. Attention
1. NLP복습

여기서 각각의 값들이 어떻게 계산되는 지 간단히 수식으로 생각해 보자면
다음과 같이 계산이 된다. 즉, 은닉층으로 부터 넘어온 값과 현재 인풋이 각각의 가중치와 곱해진 값을 편향과 더해서 다음 은닉층이 계산되고 이를 이용하여 결과 값을 만들게 된다.
-임베딩
단어들은 기본적으로 수치형 데이터가 아니기 때문에 우리가 이를 이용하여 모델을 만들기 위해서는 이를 수치형으로 바꿔주는 과정이 필요하다. 원래는 이러한 경우 주로 O-H 인코딩을 많이 사용하였었지만 이를 이용하여 문제점이 두가지 정도 존재하는데 첫번째는 인풋이 너무 커진다는 것이다. 사전의 모든 단어들을 기반으로 O-H를 진해하면 단어 한개가 인코딩 되어 나온 벡터의 길이가 매우 길어질것이기 때문에 이를 활요하다보면 일단 인풋이 담고있는 정보가 매우 Sparse해질 것이고 이를 처리하기 위한 메모리도 많이 소요되기 때문에 매우 비효율적인 인코딩 방식이라는 것을 알 수 있다. 두번째로는 원래 단어의 의미를 모두 표현하지 못한다는 것이다. 예를 들어, 학생과 대학교는 매우 비슷한 성격을 가진 단어이지만 이를 OH인코딩으로 하다보면 이러한 정보를 모두 담지 못한다.
따라서 이를 해결하기 위해 해당 단어들을 특정한 벡터 공간에 Projection시키는 과정을 진행하게 되었는데 해당 과정을 임베딩이라고 부릅니다.
주로 쓰이는 임베딩 방법은 학습을 통한 단어간의 유사도를 평가하는 Word2Vec를 많이 쓴다. 여기서 우리는 분포가설이라는 것을 짚고 넘어가야한다. 무슨 말이냐, 비슷하게 놓여있는 애들은 비슷한 의미를 가진다는 말이다. 자세한 내용은 여기서 짚고 넘어가기에는 분량이 너무 많으니 짧게 내용만 이해하고 넘어가면
전체 문장에서 저 y에 해당하는 부분만 뚫어 놓고 다음과 같은 방식으로 y를 유추해 내는 가중치 벡터를 학습시키는 것이다.
이를 텐서플로우에서 활용하는 코드는 다음과 같다.
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(1000, 64, input_length = 10)
input_array = np.random.randint(1000, size = (32, 10))
model.compile("rmsprop", "mse")
output_array = model.predict(input_array)
print(output_array.shape) #(32, 10, 64)2. Seq2Seq
앞에서 말한 RNN을 써서 기계번역을 수행했을 때는 2가지의 단점이 존재한다..
1. input과 output의 길이가 같다.
2. 단어와 단어가 같은 위치에서 1대1 대응이 되서 해석이 되어야한다.
ex) I love you => 난 널 사랑해
따라서 이를 해결하기 위해 Seq2Seq가 나오게 되었다.
사실 저 사진만 보면 모든게 설명된다. 어떠한 input이 RNN계열의 모델을 거쳐 나오게 된 context vector의 경우 input이 가지고 있는 모든 정보를 함축하고 있다는 가정하에 이를 decoder모델에 넣어서 복원을 시키게 되는 모델이 Seq2Seq이다. 이때 Decoder에게 처음 들어가는 말은 <sos>이고 decoder가 최종적으로 나오게 하는 단어는 <eos>이다.
근데 이렇게 되면 문제가 발생합니다.
1. 문장이 길면 context vector가 모든 정보를 함축하기 힘들고 이에 따라 decoder가 복원 해내기도 힘듭니다.
2. 문장의 구조적 정보를 파악해내는데는 구조적인 이점이 전혀 없다는 것입니다.
3. 해석하는 부분에서 만약 Chatbot을 만든다고 가정하면 질문을 받고 답을 할 때 대답에는 어떠한 새로운 정보가 들어갈 자기라 없습니다. 따라서 질문에 있는 정보만을 가지고 답을 만들어야 하기 때문에 이는 매우 부적절하다고 볼 수 있습니다.
3. Attention
attention을 가장 잘 표현하는 그림은 위의 그림이 아닌가 싶습니다. 허민석님 감사합니다.
위에서 말한 Seq2Seq의 문제점인 문장의 구조적 의미를 담지 못하는 문제와 context vector만을 사용해서 decoder를 구현할 때 생기는 문제를 encoder의 각 time step마다 나오는 hidden state에 가중치를 곱하고 이를 softmax를 취해 나오는 attention weight를 기존의 가지고 있는 context벡터와 concatenate를 하여 이를 활용하여 decoding을 진행하게 됩니다.
어쩌라는 거냐, 이렇게 말한다고 되냐 라는 질문이 있을 수 있죠. 역시 show me the code, 바로 코드 가겠습니다.
4. Code
아래 코드는 tensorflown2.0을 기반으로 구현된 코드 입니다. 코드는 다음 github에서 가져왔습니다.
github.com/semi-zero/NLP_study/blob/main/5.CHATBOT/5.4.seq2seq.ipynb
먼저 인코더 입니다.
class Encoder(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim, encoding_units, batch_size):
super(Encoder, self).__init__()
self.batch_size = batch_size
self.encoding_units = encoding_units
self.vocab_size = vocab_sizse
self.embedding_dim = embedding_dim
self.embedding = tf.keras.layers.Embedding(self.vacab_size, self.embedding_dim)
self.gru = tf.keras.layers.GRU(self.encoding_units,
return_sequence = True,
return_state= True,
recurrent_initializer = 'glorot_uniform')
def call(self, x, hidden):
x = self.embedding(x)
output, state = self.gru(x, initial_state = hidden)
return output, state
def initialize_hidden_state(self, input):
return tf.zeros((tf.shape(input)[0], self.encoding_units))사실 이정도 코드면 tensorflow나 torch나 구분이 없는것 같긴하지만 일단 코드에 주요한 부분 설명 드리겠습니다.
1. 임베딩 레이어를 모델에 넣어주기 전에 추가했다. 왜? 단어가 인풋이니깐
2. gru에서 return_sequence = True와 return_state = True로 지정을 하였다. 왜? return_sequence는 각 time_step마다의 hidden_vector를 출력시키기 위함이고 나머지 하나는 최종 state를 출력시키 위함입니다.
3. gru의 recurrent_initializer를 glorot_unitform을 사용했습니다. 이건 그냥 간과하기 쉬운 부분인데 gru의 recurrent activation은 sigmoid, 일반적인 mlp의 activation은 tanh입니다. 이에 따라 초기화 방식을 glorot으로 채용한 것입니다.
4. initialize_hidden_state를 정의한다. 이건 사실 그냥 sequence로 모델 만들거나 함수형 api사용하는 경우 간과를 하기 쉬운 부분인데 rnn계열 모델을 사용할 때 이 hiddent state를 초기화를 하는 것이 상당히 중요하다고 생각이 듭니다. 자연어는 당연히 매 input마다 초기화 하겠지만 시간축이 긴 데이터를 짧게 쪼개서 사이사이 값을 보고 싶은 경우 hidden state에 대한 초기화를 매 에피소드마다 진행을 해야겠죠?
다음은 핵심적인 부분인 attention 부분입니다. 해당 깃허브 제작자는 bahdanau attention을 사용하였습니다.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
hidden_with_time_axis = tf.expand_dims(query, 1)
score = self.V(tf.nn.tanh(
self.W1(values) + self.W2(hidden_with_time_axis)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
먼저 가중치를 3가지를 정의합니다. 하나는 마지막 state에 대한거, 나머지 하나는 time step마다의 hidden state에 관한거, 마지막은 이들을 더해서 tanh를 통해 나온거를 한번 더 처리하는 가중치 이렇게 3개가 정의가 됩니다. 이렇게 말만 하면 뭘 하는건지 모르겠죠?
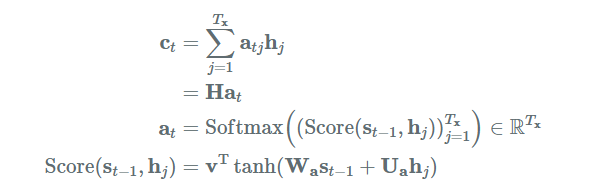
W_a가 W_1인 거고여, U_a가 W_2인겁니다. 그리고 마지막으로 저기 v가 V로 나타내어 진겁니다.
이제 Decoder 부분입니다.
class Decoder(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim, decoder_units, batch_size):
super(Decoder, self).__init__()
self.batch_size = batch_size
self.decoder_units = decoder_units
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.embedding = tf.keras.layers.Embedding(self.vocab_size, self.embedding_dim)
self.gru = tf.keras.layers.GRU(self.decoder_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
self.fc = tf.keras.layers.Dense(self.vocab_size)
self.attention = BahdanauAttention(self.decoder_units)
def call(self, x, hidden, encoder_output):
context_vector, attention_weights = self.attention(hidden, encoder_output)
x = self.embedding(x)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)
output, state = self.gru(x)
output = tf.reshape(output, (-1, output.shape[2]))
x = self.fc(output)
return x, state, attention_weights여기서 봐야하는거는 총 2가지 정도가 있습니다.
1. encoder output을 그냥 쓰는게 아니라 attention을 거친것을 사용한다.
2. reshape해서 output의 크기를 조정해준다.
사실 1번은 구현에 관련된거라 이렇게 구현했구나 라고 이해하시면 되는데 정말 항상 문제가 되는게 저 차원이죠. 저는 개인적으로 차원의 저주를 코드를 구현할 때 차원이 안 맞아서 생기는 그 긴 디버깅 시간, 그것이 차원의 저주라고 생각합니다. 여튼 여기까지가 decoder를 적용한 것이구요
핵심의 핵심 손실함수 부분입니다.
optimizer = tf.keras.optimizers.Adam()
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction='none')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy')
def loss(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
def accuracy(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
mask = tf.expand_dims(tf.cast(mask, dtype=pred.dtype), axis=-1)
pred *= mask
acc = train_accuracy(real, pred)
return tf.reduce_mean(acc)일단 뭐 SparseCategoricalCrossentropy를 사용한거는 그냥 그렇구나 한데 일단 두가지 정도 짚고 넘어가야겠네요.
1. reduction이 none이다.
왜?
2. output의 길이가 원래 label보다 길 수도 있기 때문에 이러한 부분에 대해서는 masking을 통해 손실함수를 보정한다. 이때 사용하는 loss가 원래 output과 길이가 같아야 하기 때문에 reduction을 none을 하고 마지막에 평균을 하네요.
이제 Wrapping하는 부분을 보시죠.
class seq2seq(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, enc_units, dec_units, batch_sz, end_token_idx=2):
super(seq2seq, self).__init__()
self.end_token_idx = end_token_idx
self.encoder = Encoder(vocab_size, embedding_dim, enc_units, batch_sz)
self.decoder = Decoder(vocab_size, embedding_dim, dec_units, batch_sz)
def call(self, x):
inp, tar = x
enc_hidden = self.encoder.initialize_hidden_state(inp)
enc_output, enc_hidden = self.encoder(inp, enc_hidden)
dec_hidden = enc_hidden
predict_tokens = list()
for t in range(0, tar.shape[1]):
dec_input = tf.dtypes.cast(tf.expand_dims(tar[:, t], 1), tf.float32)
predictions, dec_hidden, _ = self.decoder(dec_input, dec_hidden, enc_output)
predict_tokens.append(tf.dtypes.cast(predictions, tf.float32))
return tf.stack(predict_tokens, axis=1)
def inference(self, x):
inp = x
enc_hidden = self.encoder.initialize_hidden_state(inp)
enc_output, enc_hidden = self.encoder(inp, enc_hidden)
dec_hidden = enc_hidden
dec_input = tf.expand_dims([char2idx[std_index]], 1)
predict_tokens = list()
for t in range(0, MAX_SEQUENCE):
predictions, dec_hidden, _ = self.decoder(dec_input, dec_hidden, enc_output)
predict_token = tf.argmax(predictions[0])
if predict_token == self.end_token_idx:
break
predict_tokens.append(predict_token)
dec_input = tf.dtypes.cast(tf.expand_dims([predict_token], 0), tf.float32)
return tf.stack(predict_tokens, axis=0).numpy()사실 그냥 쭉 모델 이어진 것인데 주목해 봐야하는 부분은 inference 부분에서 내가 뱉은 prediction을 다시 사용한다 정도 인것 같습니다.
이만 tnt 4주차 발표 정리 마무리 하겠습니다. 좋은 발표 해주신 박준영님 감사합니다.
참고
ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io
Word2Vec (1) : 단어 임베딩 & CBOW 모델
An Ed edition
reniew.github.io
www.youtube.com/watch?v=WsQLdu2JMgI