[CUDA] GPU에서 코드 돌리기

병렬 프로그래밍의 종류 : SIMD vs SPMD
SIMD(Single Instruction Multiple Data), SPMD(Single Program Multiple Data)에서 알 수 있듯이 여러 데이터를 가지고 병렬로 수행하는 단위가 Instruction이냐 Data이냐 라는 차이가 존재한다.
우리가 Instruction이라는 말에서도 알 수 있듯이 SIMD는 쓰레드별 동기화가 반드시 필요하게 되고 이러한 동기화는 하드웨어의 지원으로 이뤄지게 된다. SPMD는 반면에 동기화에 대해 SIMD보다 느슨하게 이뤄지는 게 특징이다.
GPU는 이 중에 SPMD에 해당하는 Machine이다. GPU의 여러 쓰레드는 같은 code를 실행하지만 다른 데이터를 가지고 code를 실행한다.
GPU의 용어
1. Host vs Device
Host : CPU를 포함하고 있는 마더보드
Device : GPU를 의미
2. GPU의 쓰레드 단위
GPU는 여러 쓰레드가 존재하는데 이러한 쓰레드는 Warp, Block이라는 용어로 묶이게 된다.
- Block : 쓰레드가 공유메모리, Atomic operation, barrier synchronization등을 공유하는 단위로써 Block안에 쓰레드들은 같은 Streaming Multiprocessor에서 같은 시간에 수행된다.
- Warp : Thread들이 같은 instruction을 실행하는 단위를 의미한다. warp는 control part를 공유하게 되는데 이는 warp 단위로 쓰레들이 스케줄 된다는 것을 의미한다.
Warp는 Block보다 크지 않으며 Block안에 쓰레드들이 warp단위로 나뉘어져 있다고 이해할 수 있다.

3. GPU의 메모리 구조

- Global Memory : Main GPU 메모리로써 host랑 통신을 하는데 사용된다. 모든 쓰레드가 접근 가능하지만 Off chip이며 느린 메모리이다.
- Shared Memory : 같은 Block안에 Thread들이 공유하는 메모리로써 On Chip이여서 접근이 빠르다. 다만 Shared Memory의 용량은 한정적이기 때문에 Shared Memory의 사용이 GPU안에서 Block 단위를 결정할 수도 있기 때문에 사용에 주의가 필요하다.
- Local Memory : 각 쓰레드 별로 private한 memory이며 Register overflow가 발생할 시 데이터가 저장되는 곳이다.
- Constant Memory : Read Only한 메모리 공간으로 모든 쓰레드에 의해 접근 가능하다. Off Chip이지만 빠르다는 장점을 가지고 있다.
- Texture Memory : Read Only한 메모리 공간으로 모든 쓰레드에 의해 접근 가능하다. Off Chip이지만 캐시 개념이 도입되어 cache hit이 발생하게 되면 빠르게 데이터를 불러올 수 있다. 주로 2D Locality기반 cache 정책을 가지고 있다.
GPU에서 코드 실행시키기
우리가 앞써 살펴본 Thread와 Block은 인덱스가 존재한다. 이들은 Block과 Thread의 구조의 차원이 몇이냐에 따라 인덱스를 달리 가지게 된다.
GPU에서 데이터의 분배는 이러한 인덱스를 기반으로 동작한다.
GPU에서 작동하는 코드는 다음과 같은 과정을 거쳐 실행이 된다.
1. CPU 메모리에서 GPU의 메모리로 데이터를 복사한다.
2. GPU 프로그램을 로드하고 실행시킨다.
3. GPU 연산의 결과를 CPU 메모리로 이동시킨다.
각 과정을 코드로 살펴보도록 하자. 해당 코드는 GPU를 사용하여 벡터의 덧셈을 진행하는 코드이다.
1. 초기화 단계
void vecAdd(float* A, float* B, float* C)
{
int size = n * sizeof(float)
float* A_d, B_d, C_d
cudaMalloc((void**)&A_d, size);
cudaMalloc((void**)&B_d, size);
cudaMalloc((void**)&C_d, size);
}우리가 데이터를 보내기 전에 GPU에 전달할 메모리가 도착할 공간을 Global Memory에 할당해야한다. 이를 위해 A_d, B_d, C_d를 선언한 것이라고 보면 된다. 이후 cudaMalloc을 통해 Device의 메모리 공간의 주소에 데이터를 위한 공간을 할당한다.
2. Host에서 Device로 메모리 전달
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);앞써 정의한 주소 공간에 우리가 보낼 A, B라는 데이터를 전송한다.
3. Host Code와 Device Code정의
먼저 Device에서 실행할 코드를 작성한다.
__global__
void vecAddKernel(float* A_d, float* B_d, float* C_d, int n)
{
int idx = threadIdx.x + blockDim.x * blockIdx.x;
if(idx < n) C_d[i] = A_d[i] + B_d[i];
}여기서 우리가 주목해야할 점은 Idx를 파악하는 과정이다. 블럭의 차원과 인덱스를 곱하여 자신의 쓰레드가 위치한 블럭의 인덱스를 파악하고 쓰레드 인덱스를 더하여 전체적인 인덱스를 구하는 과정이다.
__global__은 컴파일러에게 해당 코드가 Device에서 동작할 코드라는 것을 알려주는 부분이다.
다음은 Host에서 실행할 코드이다.
int vecAdd(float * A, float* B, float* C, int n)
{
vecAddKernel << ceil (n/256), 256 >> (A_d, B_d, C_d, n);
}vecAddKernel은 우리가 앞써 정의한 vecAddKernel을 의미한다. Device에서 동작하는 코드를 Host에서 선어할 때는 다음과 같은 방식으로 함수를 호출하게 된다.
함수이름 << 블럭의 갯수, 블럭 별 쓰레드의 갯수>> (함수 인자)
GPU에서 코드를 작성할 때 주의할 점
- Resource Limit
우리가 블럭 갯수, 쓰레드 갯수, Shared Memory 용량을 선언할 때 주의해야하는게 있다. GPU별 최대 블럭 갯수, 쓰레드 갯수, Shared Memory 용량에는 한계가 있다는 것이다.
예를 들어 우리의 GPU가 쓰레드는 최대 1024개, 블럭은 최대 8개, 레지스터는 쓰레드당 10개, 최대 8192개를 가질 수 있다고 해보자. 이러한 경우 아래와 같이 변수를 할당하면 리소스 제한에 걸려 자원 낭비가 발생한다.
ex) Block별 쓰레드 할당을 8 x 8개로 한다면?
전체 쓰레드는 1024이기 때문에 총 16개의 블럭을 생성해야하지만 GPU가 생성할 수 있는 블럭의 갯수가 8개로 제한 되어있기 때문에 512개의 쓰레드는 사용하지 못하는 상황이 온다.
ex) Block별 쓰레드 할당을 16 x 16개로 한다면?
총 필요로 되어지는 레지스터의 갯수는 10 x 16 x 16이기 때문에 이를 바탕으로 블럭이 할당되면 3개가 만들어진다. 이는 3 x 16 x 16개의 쓰레드가 할당이 되어지는 것을 의미한다.
- Bank Conflict
Shared Memory에 Array들은 Bank라는 단위로 나뉘게 된다.
우리가 만약 Bank에 다음과 같은 구조체가 있다고 가정하자.
struct bank {
float x, y, z;
};Bank Conflict란 여러 Thread가 하나의 Bank의 서로 다른 아이템들에 접근하려고 할 때 conflict가 발생하여 쓰레드 별 접근 순위가 생기는 것을 의미한다. 예를 들어 Thread 0이 bank.x에 접근할 때 Thread 1이 bank.y에 접근하려고 할 때 0과 1이 동시에 데이터에 접근하지 못하는 것을 의미한다.
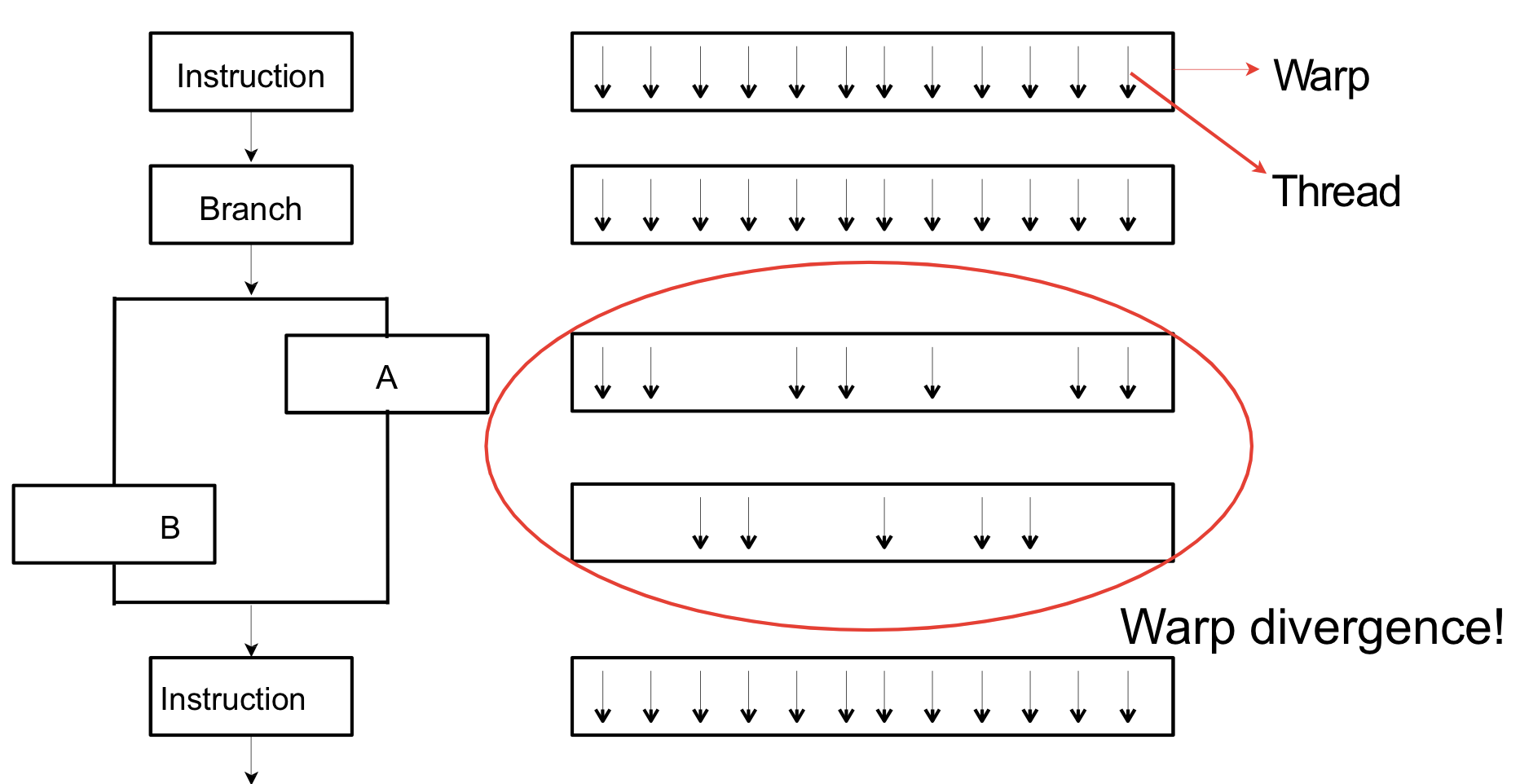
- Warp Divergence
같은 Warp내에 있는 Thread들은 같은 instruction을 수행한다. 따라서 warp가 분기문을 만나면 index에 따라 특정 Thread들이 유휴 상태로 들어가게 되는데 이를 Warp Divergence라고 한다. 이를 표현하면 다음과 같은 그림으로 표현이 될 수 있다.
성균관대 남범석 교수님의 SWE3032 강의를 듣고 정리한 글입니다.
긴 글 읽어주셔서 감사합니다.
틀린 부분이 있으면 댓글을 달아주시면 감사하겠습니다.
📧 : may3210@g.skku.edu