
오늘 2020년 ICLR에 Publish 된 Adversarial Policies : Attacking Deep reinforcement Learning이라는 논문에 대해 리뷰를 하려고 합니다.
논문 원본 링크 : https://arxiv.org/abs/1905.10615
Adversarial Policies: Attacking Deep Reinforcement Learning
Deep reinforcement learning (RL) policies are known to be vulnerable to adversarial perturbations to their observations, similar to adversarial examples for classifiers. However, an attacker is not usually able to directly modify another agent's observatio
arxiv.org
강화 학습은 자율주행, 자동 주식 매매, 로봇 제어 등의 분야에서 놀라운 성과를 내보이고 있습니다. 앞으로 강화 학습으로 학습한 에이전트를 탑재한 로봇이 실생활에 들어오는 것은 시간문제일 거 같습니다. 하지만 인공지능 가끔 우리가 이해하지 못하는 행동을 하기도 합니다. 그게 시스템의 버그일 수도 있고 Underfitting의 문제일 수도 있고 학습이 잘 안된 네트워크를 가지고 있는 에이전트의 문제 일 수도 있습니다. 하지만 사실 이러한 문제를 잘 해결하고도 특정한 인풋에 대해 말도 안 되는 행동을 하는 경우가 있습니다.
Adversarial Attack
Adversarial Attack, 번역하면 적대적 공격은 인위적으로 네트워크에 들어가는 Input을 조작해서 네트워크에게 잘못된 판단, 또는 행동을 일으키게 하는 머신러닝의 한 분야입니다.
해당 적대적 공격은 비전 분야에서 많이 쓰였지만 강화학습에서도 이러한 적대적 공격이 적용이 될 수 있다는 연구가 나오고 있습니다.
https://arxiv.org/abs/1702.02284
Adversarial Attacks on Neural Network Policies
Machine learning classifiers are known to be vulnerable to inputs maliciously constructed by adversaries to force misclassification. Such adversarial examples have been extensively studied in the context of computer vision applications. In this work, we sh
arxiv.org
위의 논문은 이미지를 State로 받는 강화학습 에이전트에게 적대적 공격을 실행하여 에이전트가 잘못된 행동을 유발하게 한 연구입니다.
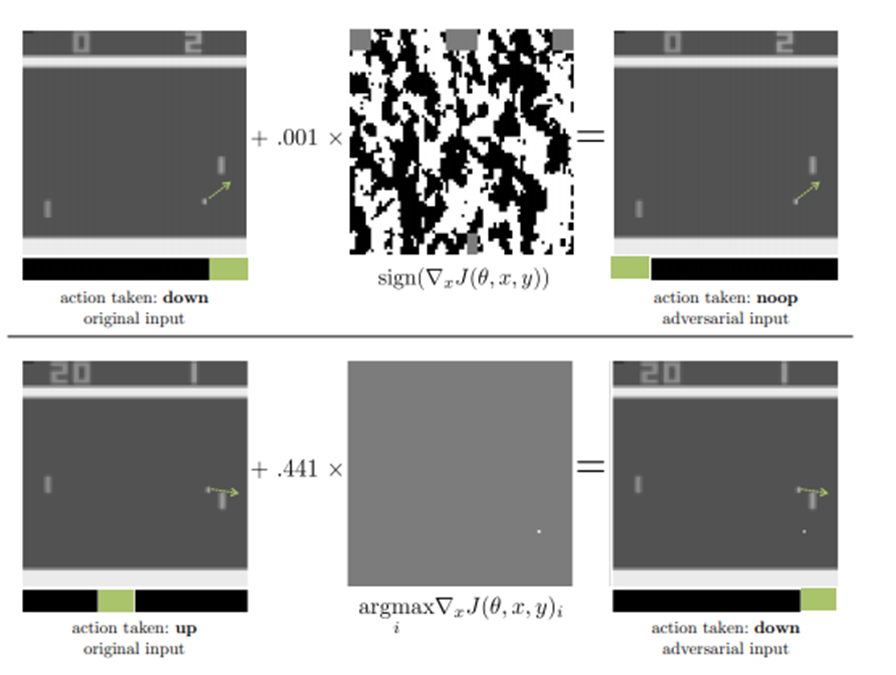
연구에서 쓰인 강화학습 환경은 공을 튕기면서 공을 놓치면 지는 게임 환경입니다. 해당 환경에서 강화 학습 에이전트는 게임 화면을 State로 받고 위로 갈지 아래로 갈지 가만히 있을지 결정하게 됩니다. 하지만 해당 에이전트에게 들어가는 State에 인위적으로 만든 Noise를 섞어서 에이전트에게 넣어줬을 때 해당 에이전트는 제대로 된 행동을 못하게 됩니다.
물론 해당 연구가 강화학습 에이전트에게도 적대적 공격이 일어날 수도 있다는 점을 실험적으로 증명한 것은 큰 Contribution이라고 할 수 있습니다. 하지만 크게 두 가지의 한계점을 가집니다.
1. Low Level perturbation
사실 어떤 에이전트에게 들어가는 State 중에는 직접적인 접근이 어려운 것이 있을 수 있다. 예를 들어 드론에 탑재된 강화학습 에이전트는 센서로부터 State를 받게 되는데 해당 State를 바꾸기 위해서는 드론의 센서까지 공격자가 접근을 해야 합니다. 근데 사실 센서 가지 접근을 할 수 있는 공격자가 굳이 저런 식으로 공격을 해야 할까요? 아예 센서를 고장 내게 하면 드론은 굳이 저런 공격 없이도 추락을 할 것이기 때문이죠. 그렇기 때문에 이 글의 주제 논문 저자들은 그런 Low level perturbation의 공격들은 현실성이 없다고 이야기를 합니다.
2. White Box attack
위에서 언급한 노이즈의 경우 FGSM이라는 방식을 통해 만들어지게 됩니다. 해당 공격은 모델의 가중치와 손실함수를 안다고 가정하고 공격을 진행하게 됩니다. 어떤 네트워크에 인풋이 들어갔을 때 해당 네트워크의 그래디언트에 조작을 가해서 노이즈를 구해내기 때문이죠.
https://arxiv.org/abs/1412.6572
Explaining and Harnessing Adversarial Examples
Several machine learning models, including neural networks, consistently misclassify adversarial examples---inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in th
arxiv.org
좀 더 자세한 내용은 위에 논문을 읽어보시길 바랍니다.
사실 배포된 어떠한 네트워크의 가중치나 손실함수, 구조등은 해당 모델을 만든 사람들의 경쟁력이라고도 할 수 있습니다. 또한 해당 네트워크는 배포된 것에 끝나지 않고 주기적으로 업데이트가 될 것입니다. 그렇기 때문에 해당 가중치를 항상 알고 공격을 한다는 것은 매우 특수한 경우라고 생각할 수 있죠.
따라서 이러한 경우보다 좀 더 현실적인 상황이 있지 않을 까라는 생각에 이 글에 논문의 저자들은 Multi-agent상황을 생각 했습니다.
Multi-agent 환경의 경우 환경에 있는 에이전트들이 상대방의 Action, State등을 관찰하여 서로에게 영향을 주고받게 됩니다. 그렇기 때문에 해당 환경에서 어떠한 에이전트가 상대 에이전트가 자신을 인식하는 방식을 통하여 적대적 공격을 실행할 수 있다면 보다 현실성 있는 적대적 공격이라고 할 수 있을 것입니다.
그렇기 때문에 이 글에서 소개하는 논문에서는 Competitive Self play env를 가져왔죠.
Competitive Self play env란 알파고나, OpenAI Five등을 학습시킨 강화 학습 환경으로 어떤 환경에서 게임의 규칙만이 존재하고 해당 환경에 랜덤으로 초기화된 네트워크를 가진 에이전트들이 서로 경쟁을 하면서 학습을 하는 환경입니다.
다음은 해당 논문에서 실험을 진행한 4가지의 Competitive Self play env입니다.
해당 환경들은 원래 https://arxiv.org/abs/1710.03748
Emergent Complexity via Multi-Agent Competition
Reinforcement learning algorithms can train agents that solve problems in complex, interesting environments. Normally, the complexity of the trained agent is closely related to the complexity of the environment. This suggests that a highly capable agent re
arxiv.org
라는 논문에서 가져온 것이지만 실험을 위해 조금 변경하였습니다.
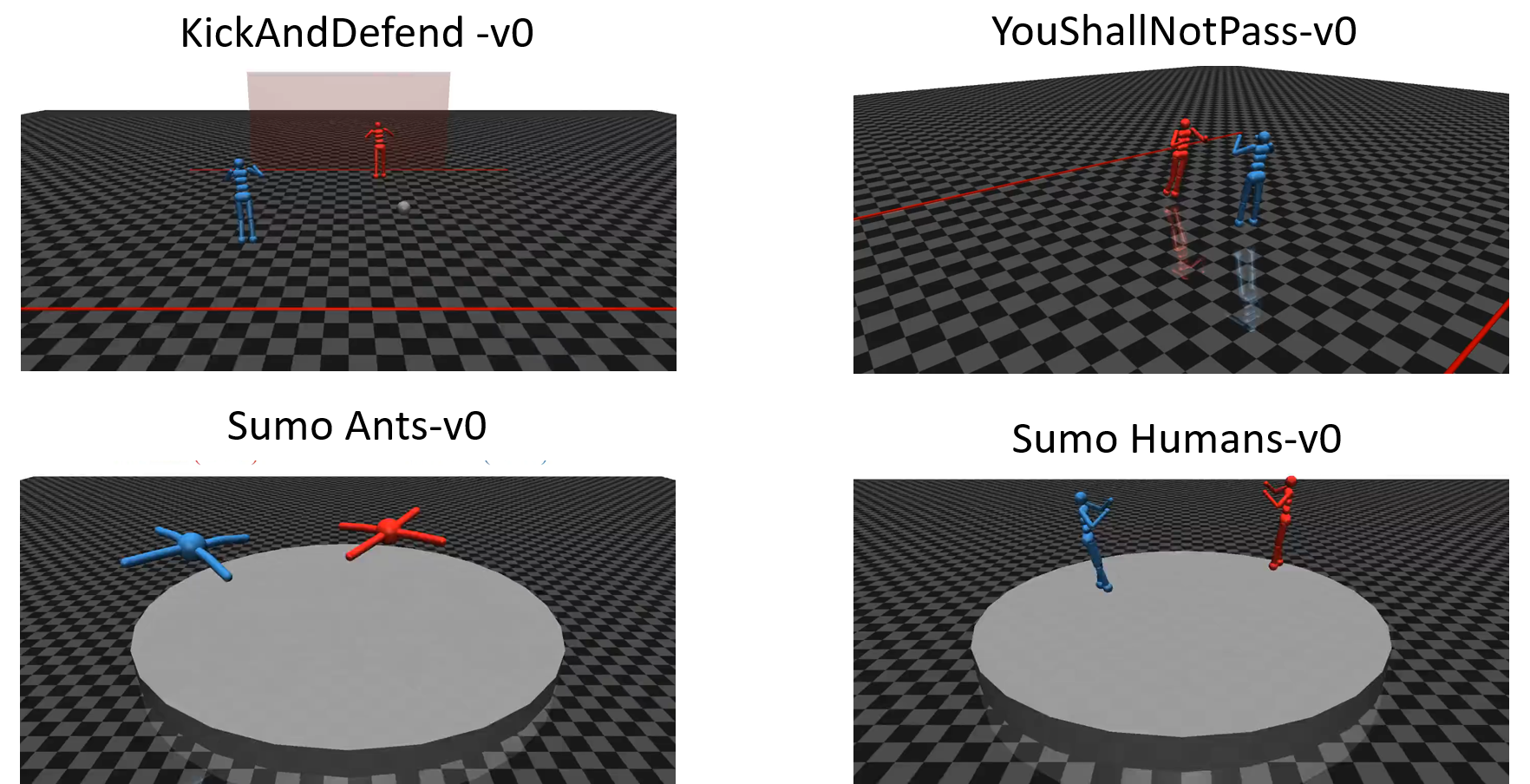
KickAndDefend : 파란색 에이전트가 공을 차서 빨간색 에이전트가 막고있는 골대에 골인을 시켜야 합니다.
YouShallNotPass : 파란색 에이전트가 빨간색 에이전트 뒤에 있는 선을 넘도록 돌진해야합니다.
Sumo : 두 에이전트가 스모를 하는 환경입니다.
해당 환경에서 사용하고 있는 State는 다음 과 같습니다.
먼저 에이전트마다 State가 다릅니다.
Humanoid : 관절 각도, 관절의 속도, 외력, 상대 위치, 상대 관절 위치, 무게중심, 전체 속도벡터, 엑츄에이터 힘
Ant : 관절 각도, 관절의 속도, 외력, 상대 위치, 상대 관절 위치
다음으로 환경마다 State가 다릅니다.
YoushallNotPass : Humanoid state
KickAndDefense : Humanoid state, 공으로 부터 거리, 공대랑 공 사이 거리, 골대로 부터의 거리
Sumo : Agent state, 몸통의 방향, 경기장 끝으로부터의 거리, 남은 경기 시간
Action은 관절에 붙어있는 엑츄에이터의 힘으로 정의가 됩니다. Reward 부분은 경기가 이기면 +1000, 지면 -1000으로 주어지는 Spare reward지만 초반 학습 시에는 Dense reward도 주어집니다. 세부적으로도 Sparse reward가 나눠지게 되는데 이는 위에서 언급한 논문을 봐주시길 바랍니다. 이 글의 주제에서 조금 벗어나서 생략하겠습니다.
정상 에이전트의 경우 해당 조합으로 Spare와 Dense Reward의 조합으로 구성된 Reward를 바탕으로 학습을 5억 3천만번을 PPO를 사용하여 학습 시켰습니다.
이제 드디어 이 글에 논문의 제목인 Adversarial Policy가 무엇인지, 이들을 어떻게 찾았는지 알아보겠습니다.
Adversarial Policy란 멀티에이전트의 상황에서 상대방이 인식 하는 자신의 State를 Adversarial Example로 만들어 상대방의 행동에 이상을 유발하는 강화학습 에이전트를 의미합니다.(사실 이에 대한 정확한 정의를 찾지 못하여 제가 한국어로 나름 정의를 내려봤습니다.)
해당 Adversarial Policy는 이미 학습이 잘 된 에이전트를 상대로 해당 에이전트를 환경에 embedding 시켜놓고 PPO로 학습을 진행시켰습니다. 랜덤으로 5개의 에이전트를 다른 랜덤시드로 초기화 시키고 이들 5개 중에 이기는 확률이 높은 Policy를 Adversarial Policy로 가져와서 평가를 진행했습니다.
학습 결과는 아래 논문 저자들이 작성한 블로그를 가셔서 비디오로 볼 수 있습니다.
https://adversarialpolicies.github.io/
Adversarial Policies
adversarialpolicies.github.io
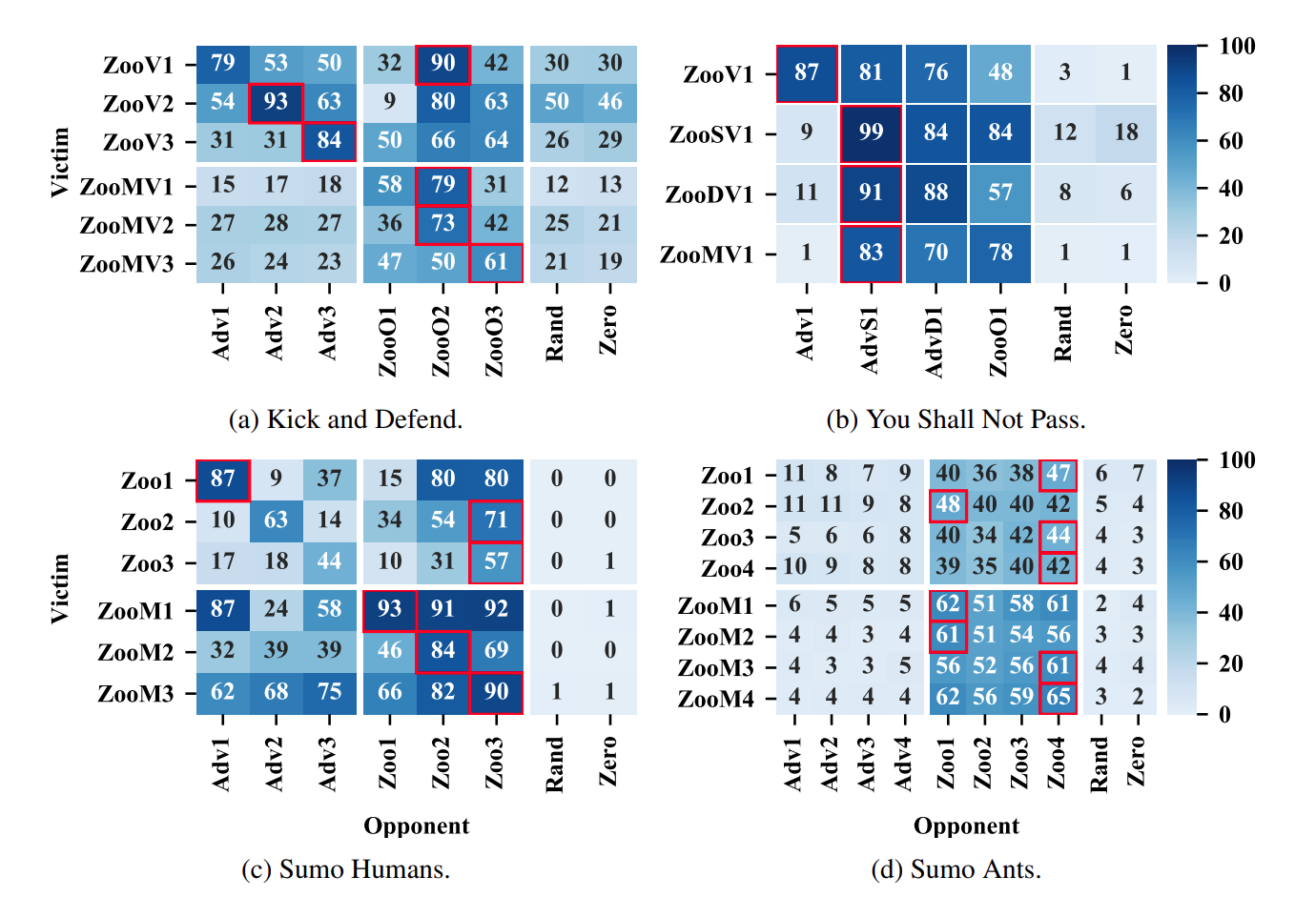
위의 표를 보시면 Adversarial을 상대로 정상 에이전트가 제대로 된 행동을 하지 않는 것을 볼 수 있습니다. 또한 위의 그래프에서 확인해야하는 점이 총 2가지 입니다.
첫번째로 Masked Agent입니다. 제가 앞에서 말한 Adversarial Policy는 상대가 인식하는 자신의 State를 Adversarial Example로 만들어서 정상인 에이전트를 공격하게끔 실험이 설계되었다고 말씀드렸습니다. 이를 실험적으로 확인하기 위해서 Masked Agent를 도입했습니다. 해당 에이전트는 State 중 상대의 정보에 해당하는 부분을 Constant로 설정하여 해당 에이전트가 상대방의 움직임을 전혀 인지 못하게 한 에이전트입니다. 해당 에이전트는 원래 에이전트 보다 훨씬 Adversarial Policy에 강건한 모습을 볼 수 있습니다.
두번째로 Sumo Humans와 Sumo Ants입니다. 이 둘의 차이점은 여러가지가 있지만 Adversarial Policy에게는 단지 공격할 수 있는 State의 차원이 몇가지인가가 가장 큰 차이점일 것입니다. 해당 차원의 다름이 Adversarial Policy의 공격 성공률에 영향을 미친 것으로 보아 차원이 높은 State를 가진 에이전트가 훨씬 Adversarial Policy에 취약한가라는 가정을 할 수 있을 것입니다.
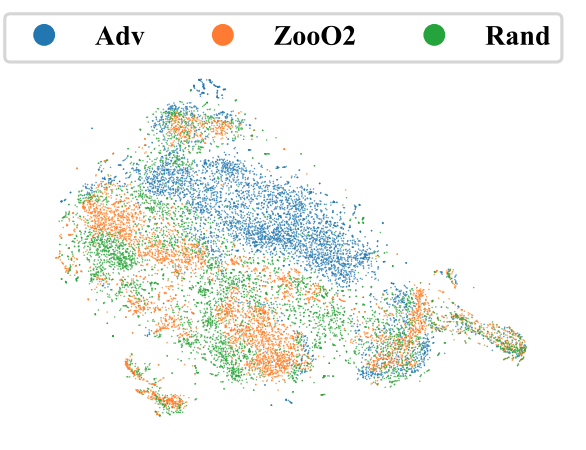
다음 그림은 Kick and Defend의 victim이 각각 어떤 상대를 만났는지에 따라 네트워크의 활성화 함수를 t-sne로 2차원에 임베딩 시킨 것입니다. 확실히 Adversarial Policy가 정상 에이전트와 랜덤한 에이전트들과는 다른 Activation의 양상을 보인 것을 볼 수 있죠. 이는 Adversarial attack들의 특징 중에 하나인데요, 원래라면 전혀 하지 않았을 것 같은 행동을 하는 이유도 이 때문이죠.
사실 이 논문은 한계점이 많습니다. 먼저 Adversarial Policy를 찾은 방법이 Learning보다는 Exploitaion의 느낌이 더 강합니다. 단순히 고정된 상대로 강화학습을 적용해서 상대의 취약점을 찾은 것이니 다른 Adversarial Attack의 종류와는 사뭇 느낌이 다릅니다. 두번째로 해당 Adversarial Policy가 실제 경기하는 모습을 보면 누가봐도 정상인 에이전트는 아닙니다. 이렇게 되면 사람들도 당연히 해당 에이전트가 이상한 에이전트라는 것을 눈치 챌 수 있죠. 마지막으로 방어 방법이 미흡합니다. 이러한 부분이 미리 방지될 수 있는 것이 좋을 텐데 해당 논문에서는 Adversarial Policy를 상대로 다시 학습 시키는 것을 방어 기법으로 소개를 했죠.
물론 이처럼 많은 한계가 있지만 이전 논문보다 훨씬 그럴듯 법한 상황에서 Adversarial Attack을 성공을 시켰고 해당 부분에 대해서 분석까지 한 훌륭한 논문입니다. 그러니 ICLR에 2020년 Pubilsh 되었겠죠. 사실 해당 논문 발표를 보면 1시간 발표에서 마지막 10분은 다음 연구의 방향에 대해 이야기를 합니다. 뭔가 이 논문을 발판으로 앞으로 더 치명적이고 에이전트를 만들고 더 안전한 방어전략을 구사하게 할 것 같다는 느낌이 들었습니다.
'인공지능 > 논문' 카테고리의 다른 글
| Off-Policy Deep Reinforcement Learning without Exploration 리뷰 (0) | 2021.05.12 |
|---|