
강화학습은 정말 매력적인 분야이다. 못 걷던 로봇을 걷게 하고, 로봇이 물체를 알아서 집게하고, 사람보다 게임을 더 잘하게 되고 심지어 자동차도 스스로 굴러가게 학습 시킬 수 있다.
그렇다면 이러한 강화학습이 지도학습에 비해서 널리 쓰이지 못하는 이유가 무엇일까? Sergey Levine 교수님의 설명을 빌리자면
“The fact that reinforcement learning algorithm provide a fundamentall online learning paradigm is also one of the biggest obastacles to their widespread adoption”
라는 것이다. 즉, 우리가 강화학습은 online learning의 성격이 강해서 이를 실제 환경에 적용하기 힘들다는 것이다. 자동차를 예로 들면, 강화학습을 이용해서 자율주행을 학습 시킨다고 했을 때 우리는 시뮬레이션이 필요하다. 근데 좋은 시뮬레이션이라는 것은 무엇일까? 이는 쉽게 이야기 할 수 있는 주제가 아니다. 시뮬레이션에서 도로상황을 최대한 비슷하게 구현하려고 했어도 실제 환경과 다를 수 밖에 없다. 그래서 우리가 아무리 시뮬레이션에서 학습을 많이 시켜도 우리는 실제 환경에 적용 해볼때 fine tuning이나 online to offline 문제를 겪게된다. 극단적으로 이야기를 해도 만약 도심에서 운전을 잘해도 사막이나 오프로드에서는 운전을 잘 못 할 수 있다. 그렇다면 어떻게 우리는 이런거를 다 커버할 수 있을까?
사실 답은 근처에 있다. 지도학습은 실제 환경에서 데이터를 뽑아서 이를 통해 학습을 진행시키기 때문에 실제 환경에 적용해도 비슷한 성능을 내보인다. 즉, 우리가 data driven learning을 강화학습에도 적용 시킬 수 있다면 위에서 언급한 문제는 모두 잘 풀린다.
이제 여기서부터 이 논문이 시작된다.
과연 data만을 가지고 RL을 학습 시킬 수 있을까?
쉽게 생각 해 볼수 있는 분야는 off-policy 알고리즘이다. 만약에 우리가 로그 데이터를 엄청 쌓아두고 해당 로그 데이터를 바탕으로 off policy를 돌리면 되지 않을까? 라는 것이다. 말로만 보면 매우 그럴듯한 상황이다. off policy라는 것은 behaivor network랑 target network가 같을 필요가 없기 때문이다.

해당 그림에서 2번째의 사진이 off-policy알고리즘을 설명하는 그림이다. 우리는 현재 policy를 업데이트 하기 위해서는 그 전에 우리가 쌓아놓은 데이터들을 기반으로 학습을 할 수 있다 라는 것이다. on-policy는 이에 반해 우리가 현재 policy를 업데이트 하기 위해서는 해당 policy가 환경과 소통해서 뽑아 놓은 데이터를 가지고 우리가 해당 policy를 학습 시켜야 한다는 것이다.
그러면 off-policy가 이야기 하는 것처럼 데이터를 무진장 많이 쌓아두고 이를 batch에서 샘플링하고 이를 바탕으로 agent를 학습 시키면 되지 않을까? 그럼 우리가 지도학습에서 학습을 하는 방식처럼 offline learning을 할 수 있지 않을까?
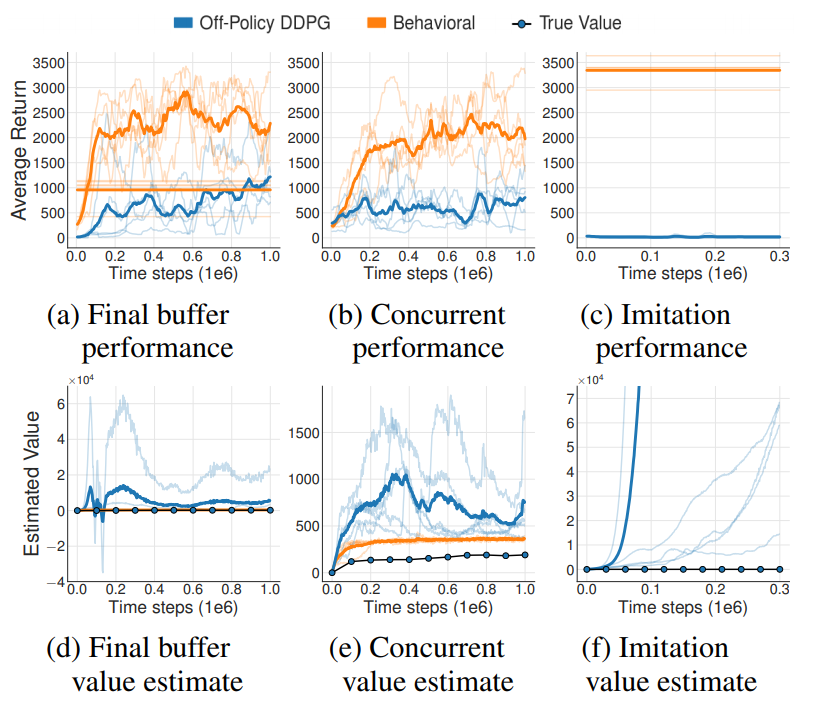
그런 의문점 때문에 진행한 실험 이다.
해당 실험에서는 주황색은 일반적인 DDPG알고리즘 이다. 파란색은 그에 반해 환경과 소통을 전혀 하지 않은 DDPG이다. (a)의 경우 주황색 agent가 학습 시 사용했던 마지막 버퍼를 가져와서 학습에 사용했던 것이고, (b)의 경우 주황색을 학습 시키면서 버퍼를 공유해서 파란색을 학습 시키는 것이다. 마지막으로 (c)의 경우 학습이 끝난 DDPG agent를 환경에서 실행을 시키면서 데이터를 얻은 것이다. (d), (e), (f)의 경우 각각 (a), (b), (c)의 경우에서 critic에 대한 결과를 나타낸 것이다. 학습 결과를 보시면 먼저 critic이 학습이 안 된 것을 알 수 있다. 이런 오류가 발생했는지에 대한 이유로 논문에서는 Extrapolation Error가 그 이유라고 이야기를 한다. 해당 Error는 버퍼에 파란색 에이전트가 뽑아낸 (s, a)에 대한 값이 없기 때문에 우리가 Q-learning을 진행 할때 학습이 제대로 안된다는 것이다.

예를 들어 우리가 버퍼에서 (s, a, r, s')이 추출 했을 때 그거에 대한 greedy action을 a'으로 우리의 파란색 에이전트가 했다고 해봅시다. 근데 만약 우리가 (s', a')가 버퍼에 없다면 우리는 그 상황에서의 Q value값을 예측하는 과정을 겪어 보지 못했을 것입니다. 그러한 상황에서 우리는 해당 Q값을 제대로 estimation 못 해내기 때문에 현재의 Q값인 Q(s, a)또한 제대로 학습이 안 된다는 것이죠.
그럼 우리가 당연히 (a), (c)는 버퍼가 고정되기 때문에 (s', a')이 없는 건 알겠는데 b의 경우는 그게 버퍼에 없는 거는 주황색 에이전트도 마찬가지 아닌가 라는 생각이 들 수 있습니다. 사실 주황색의 경우 초반에는 어느정도 on-policy의 성격을 띌 수 밖에 없습니다. 왜냐면 버퍼에 아무것도 없는 상태에서 데이터를 뽑아내기 때문이죠. 하지만 파란색의 경우 처음부터 off-policy학습이 진행이 됩니다. 즉, 초반에 (s', a')에 대한 정보가 너무 없는 거죠. 그러한 초반의 Extrapolation error가 전체 학습과정을 망치기에 충분하다는 것을 의미한다고 보시면 될 것 같습니다.
그럼 어떻게 이러한 문제를 극복 할 수 있을까요? Extrapolation에 대한 수식을 봐보시죠.
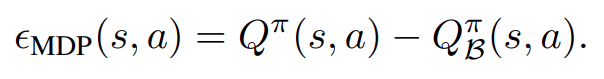
우리는 Extrapolation Error를 다음과 같이 표현 할 수 있는데요. 우항에 오른쪽 값이 우리가 찾고자 하는 Target값이고 오른쪽이 batch에서 데이터를 뽑았을 때 그걸로 학습한 Q값이라고 보면 우리는 당연히 원래 우리가 측정하고자 하는 Q와 실제 학습 해보니 얻을 수 있는 Q값에 대한 차이로 Extrapolation을 정의 할 수 있습니다.
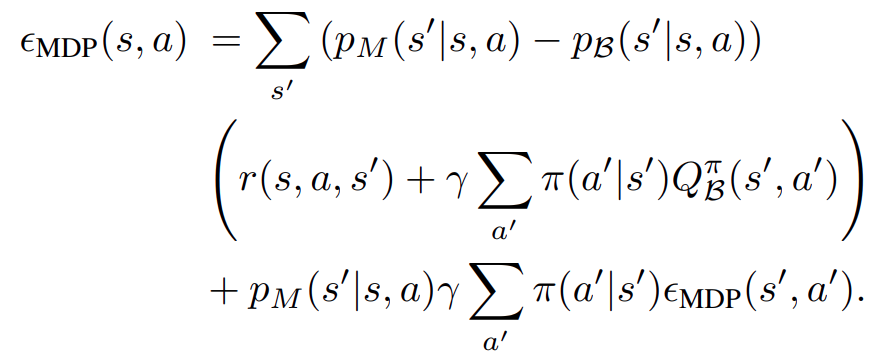
해당 수식을 전개해보면 다음과 같이 정리할 수 있는데요. 여기서 우리는 두가지를 알 수 있습니다. 우리가 만든 action을 이용한 (s, a, s')에 대한 상태천이함수가 우리가 목표로 하는 상황에서와 우리가 학습과정에서 사용하는 상황에서 같다면 그리고 전체 Trajectory에서 Extrapolation error가 0인 부분이 있다면 꼬리에 꼬리를 물어 전체 Trajectory에 대한 Extrapolation Error가 0이다 라고 이야기 할 수 있을 것입니다.
여기서 힌트를 바로 얻을 것입니다. 만약 우리가 버퍼에서 있는 (s, a, s')을 뽑으면 해당 쌍에 대한 상태천이 함수는 모두 버퍼에서 샘플링 된 것이기 때문에 같게 될 것입니다. 따라서 우리가 만약 buffer에 있는 Trajectory와 MDP를 따라가게 한다면 우리는 전체 Extrapolation Error에 대해 0으로 가져갈 수 있을 것입니다.
이를 정리하면 다음과 같죠.

위의 내용에서 우리가 Optimal Policy를 찾기 위해서 Q를 maximize하는 부분만 추가 하였다.
따라서 해당 논문 저자는 다음과 같은 인싸이트를 얻었다고 말을 하였는데요.
"Only choose π such that we have access to the (s,a) pairs π visits "
즉, 우리가 근사해야 하는 것은 s가 들어왔을 때 버퍼에서 할 법한 action을 뽑아내는 것이다. 이 부분은 어디서 많이 들어봤을 거고 당연히 VAE를 써야겠다는 생각으로 이어질 것이다.
이를 바탕으로 설계된 Batch constrained Q learning은 다음과 같다.

해당 알고리즘에서는 사용하는 Network는 총 7개이다. Clipped Double Q learning 을 사용하기 때문에 Q network가 2개와 Actor에 해당하는 Peturbation Network. 그리고 해당 알고리즘의 하이라이크 VAE이다. 또한 앞에서 말한 Q network와 Actor network를 soft learning을 하기 위해서 각각의 target network가 존재한다.
학습 과정은 역시 코드를 보면서 이야기하면 좋을 것 같다.
코드는 해당 알고리즘 작성자의 github에서 가져왔다.
sfujim/BCQ
Author's PyTorch implementation of BCQ for continuous and discrete actions - sfujim/BCQ
github.com
해당 알고리즘 순서대로 설명해 보면
1. VAE

코드에서 알수 있다 싶이 encoding 부분은 state와 action을 받게 되서 latent dim에 맞는 z로 projection을 시킨다. 이때 VAE를 사용하는 만큼 z를 정규분포에서 sampling하는 것을 볼 수 있다.
decoding 부분은 먼저 z를 샘플링하게 된다. 이때 torch.randn을 쓰는 것으로 알 수 있다 싶이 해당 z를 표준 정규분포의 분포와 근사하도록 loss term에서 consentration을 걸것이라 생각 할 수 있다.
이후 해당 z와 우리가 계산하고자 하는 state를 concatenate를 하여 새로운 action을 뽑는데 다만 해당 action space를 모든 환경마다 설정하는게 아니라 max_action * tanh(a)으로 처리를 하는 것을 볼 수 있다.
2. Q - Network

Q-network는 단순하다. 앞서 말했듯이 Double Q-network를 사용하기 때문에 foward 부분에서 우리는 q1과 q2가 나오는 것을 볼 수 있다. 이는 사실 Q에 대한 학습에서만 사용하기 위해서라 q1이라는 함수를 따로 만들어 우리가 action을 택할 때는 해당 q1만 사용하도록 하는 것을 볼 수 있다. 근데 사실 두개 다 똑같은 td-target을 두고 학습을 진행할 것이기 때문에 이렇게 하는 것 같다. 그게 아닌 다른 이유가 있다면 댓글로 알려주시면 감사드리겠습니다.
3. Perturbation network(Actor)

해당 Actor는 저자께서 말씀하신 RL trick을 위해서 사용하는 부분인 것 같다. 해당 forward 부분을 보면 값에 phi를 곱하고 이를 원래 action에 더하고 이를 clamping한 것을 볼 수 있다. 이는 앞써 VAE를 통해 뽑아낸 action에서 우리가 어느정도 boundary를 두고 action을 뽑아내여 우리가 원하는 optimal policy를 찾는 과정이라고 할 수 있다. 또한 해당 actor를 policy gradient를 업데이트를 함으로써 DPG와 같은 맥락으로 가져갈 수 있다.
4. Train
학습 과정은 먼저 배치에서 sampling을 하고 VAE를 거치게 한다.
- VAE

VAE는 reconstruction, 평균, 편차 를 만들어 낸다. 이 때 reconstruction 과 배치 상의 action과의 MSE를 통해 state가 들어갔을 때 데이터 분포에 있는 action을 뽑아내게 하는 것에 목적이 있다. 또한 앞서 말했듯이 중간 latent vector를 표준 정규분포에 근사시키기 위해 z에 대한 분포를 KL divergence를 통해 cosentration을 주게 된다.
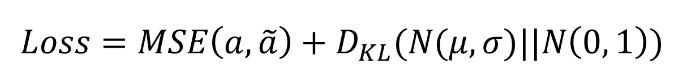
- Q network

state를 받고 이에 대해 actor를 거치게 되면 우리가 해당 state에서 할 법한 action을 10개를 뽑아내게 되는데 이에 대해서 상태가치함수를 뽑게 된다. 이후 Q를 계산하기 위해 Q1과 Q2를 Double Q에서 Q를 뽑아내듯이 계산하게 된다.
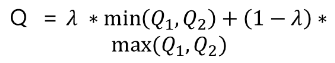
이에 대해 greedy action을 선택하여 Td-target을 구하고 이를 이용하여 Q네트워크를 학습시킨다.
- Perturbation Network

이후 Perturbation network는 당연히 우리 뽑아낸 action의 Q 기댓값이 최대화 되게끔 학습을 진행 시킨다.
- Soft update

이후 Q와 Actor에 대한 Target network를 학습 시킨다.
해당 알고리즘의 성능은 다음과 같다.

(a)는 DDPG가 학습할 때 마지막으로 사용한 버퍼를 사용하였고 (b)의 경우 DDPG학습과정에서 같은 버퍼를 공유하여 학습을 진행시킨 것이고 (c)는 이미 전문가인 agent를 이용하여 데이터를 버퍼에 쌓은 것이다. 마지막으로 (d)의 경우 무작위적 random action agent를 이용하여 버퍼에 데이터를 쌓은 경우이다.
모든 경우 BCQ가 매우 잘하는 것을 볼 수 있다. 또한 앞에서 말한 부분에서 VAE만 사용하여 학습을 시켰을 때를 VAE-BC로 하여 RL-trick의 성능을 볼 수 있었는데 이는 (d)에서 두각을 나타냈다. 어쩌면 당연하지만 해당 buffer에서 optimal policy를 찾는 과정을 넣음으로써 아무 의미없는 것처럼 보이는 데이터에서 우리는 좋은 성능을 내는 agent를 학습 시킬 수 있는 것을 알 수 있다.
해당 알고리즘은 Offline RL 또는 Batch RL 등이라 불리는 분야의 초석이 되는 알고리즘이다. Batch상에 데이터를 가지고 offpolicy알고리즘을 적용했을 때 발생하는 문제를 분석하고 이를 변분추론을 통해 완화시킨 알고리즘이라는 것에 Contribution이 크다. 하지만 알고리즘 자체가 DPG에 적용이 되어있고 이를 SOTA인 SAC랑 접목 시키지 않았다는게 조금 아쉬운 부분이다. 또한 처음 Extrapolation Error에 대해 말할 때 실험 결과를 DDPG만이 아닌 다른 Off-policy알고리즘 별로 분석하여 동일한 경향성을 보이는지도 분석을 했으면 좋았을 것 같다.
'인공지능 > 논문' 카테고리의 다른 글
| Adversarial Policies : Attacking Deep reinforcement Learning 리뷰 (0) | 2021.01.21 |
|---|